Entanglement Between an AI and Its Environment
TL;DR:
- We introduce a concept we call "entanglement": roughly, the amount of information that the AI has about its environment.
- We distinguish between "actual" entanglement between a specific instance of an AI and its environment and "minimum" entanglement corresponding to some task, without which solving the task is no longer viable.
- We think entanglement matters for AI evaluations. For example, we can use it to put a lower bound on the level of detail that test environments must have to be credible, which in turn affects the cost of evaluation.
This post is part of a collection of posts about AI oversight and its limitations, but it can also be read standalone.
Introduction: main concepts and motivation
To successfully solve a real-world task, the AI1 doing the solving must get some information about the environment and about its goal and have some way of affecting the environment. A question-answering oracle needs some background information, an input channel, and an output channel. A robot has sensors and actuators. A present-day LLM-based agent might have access to a GitHub repository, various tools, and a communication channel with the user. Broadly speaking, the AI is entangled2 with the environment.
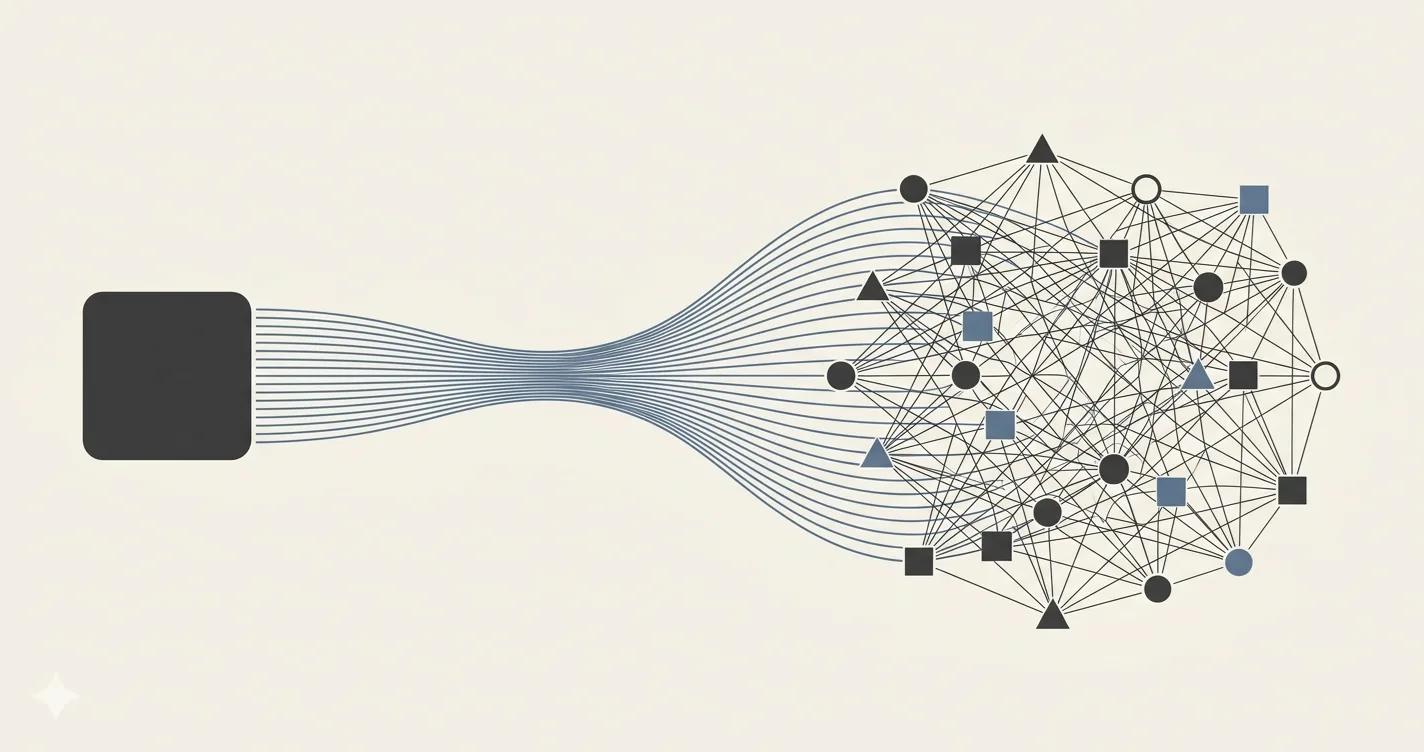
In this post, we want to point to a few interesting concepts that come up here. First, there is the qualitative question of how exactly the AI is connected to its environment, in terms of what its input and output channels are, which information it has access to, etc. Second, we have the quantitative question of how strong the connection is, or how much information the AI has about its environment. We provisionally refer to this as the actual entanglement between a particular instance of AI and the environment. Third, there is a minimum entanglement corresponding to a particular task; this is the theoretical lower bound, capturing the smallest amount of actual entanglement that some AI might have while still being able to solve the task.
We are not yet confident about the best way to operationalise these concepts, so we will avoid attempting to define them formally. For example, the descriptions are suggestive of mutual information and Shannon entropy, and we agree that these are relevant concepts — but we are not confident they capture all of what we are trying to point to here.
Ultimately, we suspect that this notion of "entanglement" is relevant to AI safety, and in particular to the questions around AI evaluations and observation-based oversight. (How expensive should we expect good evaluations to be? What are the limitations of AI oversight?) We discuss some of these connections at the end of the post.
Actual entanglement
When a specific AI is solving a specific task in a specific way, which information about the environment does the AI receive during the process? I call this actual entanglement.
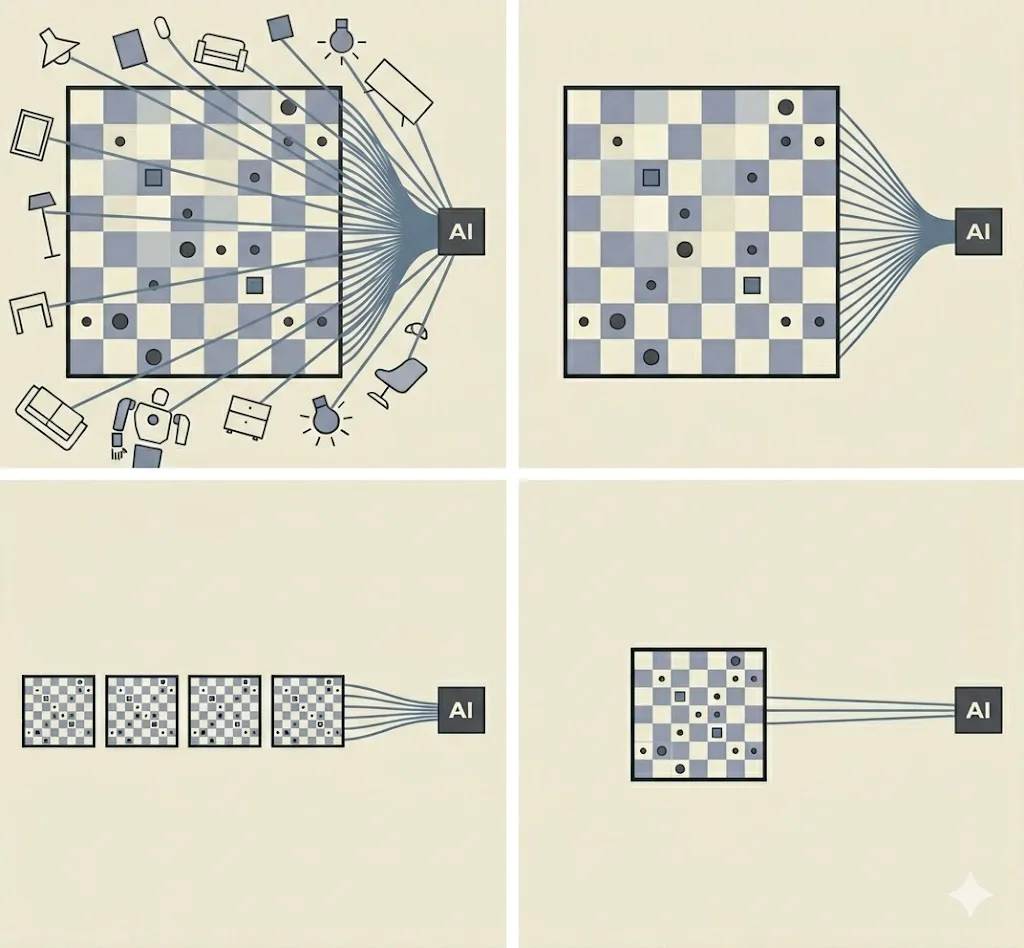
For example, suppose the task is that you want AI to help you play chess really well. One way to do it would be to have a humanoid AI-powered robot that plays the game on your behalf. Then the actual entanglement is that the robot sees the video recording of the whole game and gets sensory inputs from its body. It might also matter that the robot can walk around and choose what it looks at and interacts with.3
Very often, you can solve the exact same task with much less entanglement.
In this case, maybe instead of a robot that can move around, you just have a stationary robot with a fixed camera. Probably it's enough if the camera is black and white. But you could go even further. You don't actually need a robot at all; the AI could be software-only, and you can manually send it what moves your opponent makes — pawn to e3 — and have it tell you what moves it recommends. Now the actual entanglement is only with the history of moves in the game, not with what the room looks like.
And you can go a bit further still, for example, by resetting the AI after every turn, so instead of the whole history of play, it only ever knows the current board state.
Minimum entanglement
If you try hard enough, you could probably squeeze the information even further. For example, some board positions are equivalent up to symmetry, and you could present the position in a canonical form, hiding which orientation is the real one.
But at some point, the tricks run out. There will be some smallest amount of information you have to give the AI, below which it just can't do its job. "If you want me to help you and tell you how you should play, you have to tell me something about what is happening in the game."
There won't be a unique format for giving this information. And maybe some bits of information are interchangeable (e.g., "you need to give the AI at least two out of these four pieces of information, but it doesn't matter which two"). But the point (or perhaps conjecture?) is that there is some reasonably well-defined boundary below which no clever trick will take you. That is what I call minimum entanglement: the minimum amount of information you need to give the solver if you want the task solved.4
Properties
Now, let's go through some of the basic properties and observations regarding how this concept behaves.
Minimum entanglement depends on the performance level
One natural way to think about minimum entanglement is as a function of the task: "for task X, the minimum entanglement is Y." But this only works if the definition of the task already includes the performance level — for example, "play chess optimally" or "win against this particular opponent with probability >95%."
If you instead think of the task as "play chess" without specifying an exact performance level, things get more interesting. Let me illustrate with a different example. Suppose the task is calculating the expenses for a particular project, and you have the information on how much each component costs.
To get the exact answer, you must give the AI the exact amounts for all individual expenses — there's no way around that. But if you're willing to tolerate some error, the minimum entanglement might be lower. Maybe you're OK with an error of $1,000, in which case it might be fine to round all expenses to the nearest hundred.
So the type signature is: for each task and each required performance level, there is some minimum entanglement.
Bringing this back to chess, perhaps you could sometimes get away with giving the AI slightly incorrect information about the board state — telling it a pawn is in a different place from where it actually is. But if you do this too much, the recommendations stop working. That's why the performance level matters.
You can't cheat by solving everything at once
There is one tempting way to reduce entanglement further: instead of asking the AI how to play in your particular game, just ask it to produce a lookup table — "the optimal move for every possible board state." Now you don't need to tell the AI anything about your actual game; you just look it up.
The reason this is cheating is that you have asked the AI to solve a much harder task. Instead of one particular game, you've asked it to solve all possible games, which would be vastly more expensive.
I'm not sure about the best way to handle this conceptually, but maybe the right move is similar to what we did with performance: you look for the minimum entanglement needed to solve the task without exceeding a specific computation budget.5
You can't cheat by reshuffling the boundary
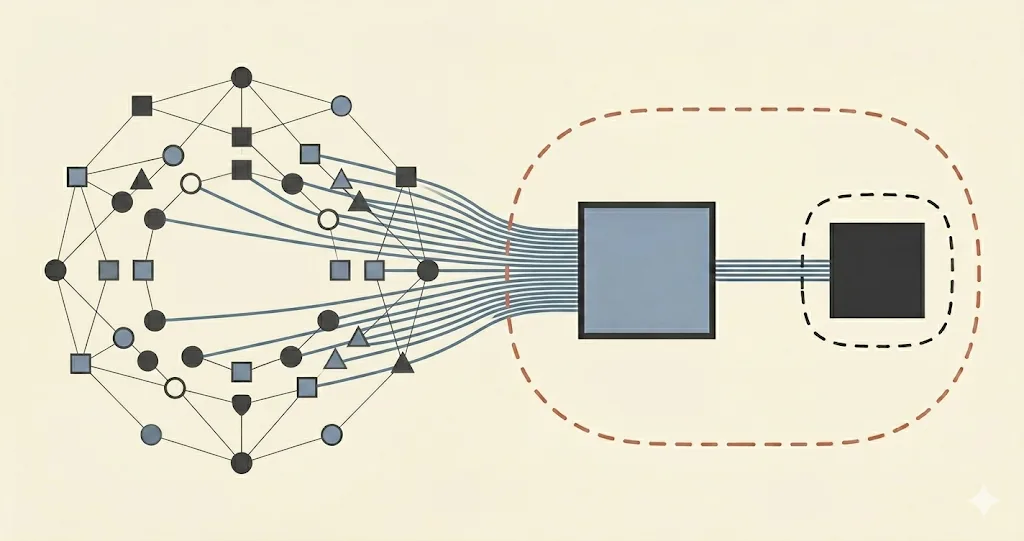
A related trick is that instead of asking the AI to tell you how to play, you ask it to give you an algorithm that tells you how to play. And the algorithm then does the actual work. If you do this, you reduce the entanglement between the original AI and the environment — perhaps even without increasing the computation, since the algorithm might be efficient.
But this is also cheating. Yes, the entanglement between the original AI and the task is now small, but all the entanglement has been reshuffled. It now sits between the algorithm and the environment. Rather than decreasing entanglement, you have only drawn the boundary between the "AI" and the "environment" in a more convenient place.6
This has practical consequences: Suppose the reason you were worried about entanglement is that an AI with too much information about the environment might try to mess with you. Unfortunately, with this reshuffling approach, you haven't solved the problem. Instead of messing with you directly, the original AI might just produce an algorithm that will try to mess with you on its behalf. And that algorithm has exactly the same amount of entanglement.7
Minimum entanglement is about a class of tasks
There is one more way you could try to cheat, and it's closely analogous to how you might try to cheat in computational complexity.
In computational complexity, we might naively ask: "How hard is it to sort this particular array?" But if you pose the question exactly like this, the answer is trivial — you can always "solve" any specific task in constant time by using the algorithm that takes empty input and outputs the correct answer for that specific task. That's why we don't ask about the complexity of specific instances but about the complexity of a class of problems.8
The same principle applies here. If you fixed the exact task ahead of time, you could design a "solver" with zero entanglement — one that simply outputs the pre-determined correct answer without looking at the environment at all. For example, a rock that has the correct answer written on it. Given that this rock would have this answer written on it, no matter what "problem" it would "face", there is no entanglement between the content of the text and the environment. It only makes sense to ask about minimum entanglement if you have uncertainty about which task you're facing — i.e., about which instance from a class of tasks you are dealing with — and are trying to solve it successfully no matter which one reality throws at you.9
Graceful vs. sharp degradation
With these properties in hand, the next question is: how does this concept behave for different types of tasks?
I conjecture that there are tasks where performance degrades gracefully as you give the solver less information, and tasks where it degrades sharply10. Some examples:
Graceful degradation. Take the problem of vacation recommendations. Suppose I'm going to a foreign country and want suggestions for which places to visit. Specifying the "full task" would mean giving the AI all the details about my trip and about me (what I like, what I dislike, my budget, my fitness level, etc.). But for practical purposes, it's enough to say "I'm going to country X during the tourist season, and I like hiking. Give me some reasonable tips." It might not give me the perfect tips, but they'll be good enough. The AI's performance degrades slowly as we decrease entanglement, and the minimum entanglement necessary for good-enough performance is low.
Sharp degradation. On the other hand, there are tasks where any single error in the information matters (or at least any error in some critical subset of the information does). If you have a self-driving car, giving it wrong information about the road could be catastrophic. If you want to get your taxes done, omitting some invoices or changing some numbers gives you an incorrect result — there is no "approximately correct" version of a tax return.11
This distinction matters because it determines how sensitive a task is to getting some of the details wrong or omitting them. With graceful degradation, I can get away with only giving the AI the most important information, and telling it to make up the rest — this won't be suspicious, since the details don't really matter that much. And as a result, creating tests for these tasks can be cheap. But if we tried the same thing with a task where performance degrades sharply, it would be suspicious. ("Hey, human, what's going on here? It looks like you don't really care about getting the right answer! Is this perhaps a test?")
Empirically, actual entanglement seems to be increasing
It is worth noting that in practice, the actual entanglement of AI systems has been increasing with each new generation of frontier AI.
For example, the context windows keep increasing, and LLMs get access to tools and web search. They get integrated into real-world systems and databases; GitHub, email, and the editor here on LessWrong. We replace pure LLMs with LLM-based agents with scaffolding and persistent memory. And we apply AI to richer and more open-ended tasks.
Each of these changes increases the amount of information about the environment that the AI can, and does, access.
This matters because with higher actual entanglement, any test environment that wants to be convincing needs to involve more information. And as AI systems become more deeply embedded in real-world workflows, the gap between "what the AI sees in deployment" and "what an evaluator can afford to fake" will grow.12
Ultimately, we care about high-stakes tasks
Admittedly, there might be real-world tasks with low minimum entanglement. Even many of them. However, the applications that matter most to me are ultimately the ones where a powerful AI might have a genuine opportunity to take over, or to significantly increase its future influence. For example:
- Helping with AI development at a frontier AI company;
- Working as a personal assistant for many people simultaneously, with the ability to coordinate between instances;
- Assisting the government or military in high-stakes situations;
- Helping run very influential companies.
How exactly minimum entanglement scales in these cases is an open question. And we could make progress on it, for example, by thinking directly about how to make evaluations for these specific scenarios.
However, in this post, I want to highlight a different agenda: Trying to understand the concept of minimum entanglement in general — how it works for all kinds of tasks, what its mathematical properties are, and how it behaves empirically for simpler tasks. And then using that understanding to answer the question for the high-stakes tasks we care about the most.
Open questions
There are several directions that seem worth pursuing:
Formalization. What is the right mathematical definition of minimum entanglement? Mutual information between the AI's outputs and the environment state is one candidate, but I'm not confident it's the right one. It might also make sense to look at formalizations from related fields — query complexity (how many queries to an oracle are needed to compute a function?), or distortion in social choice theory (how much does solution quality degrade when the solver gets less information about preferences?).13
Empirical measurement. For some of the concrete tasks we are trying to solve with AI, and some of the tasks we are trying to test for: how much entanglement do they require? How much effort went into creating various test environments? And when we compare (a) minimum entanglement with (b) how much testing effort was actually used? Is this predictive of (c) how successful the tests were? Is it predictive of when AI systems seem to have or not have evaluation awareness?
Dollars as a proxy. To start with, it might also make sense to just measure some of this in dollars or person-hours. How long do I need to spend instructing my LLM if I want it to do a task for me? How much effort goes into crafting instructions and environments for AIs? And conversely, how much money went into creating datasets, test environments, and red teaming? Is the ratio between "effort spent on real use" and "effort spent on testing" predictive of tests being informative? (For example, can you use this to predict whether the AI has evaluation awareness?) This is less theoretically satisfying than a formal definition, but it might be more immediately actionable.
Connections to AI evaluation
While we find the notion of entanglement interesting on its own, we primarily bring it up because we think it has implications for AI oversight. As the final part of this post, we discuss four ideas on this topic.
(1) Minimum entanglement gives a lower bound on the cost of creating environments
By definition, minimum entanglement corresponds to the smallest amount of information, without which it becomes impossible to give an acceptable solution to the task. When someone wants to solve a real-world task, they will necessarily provide the solver with this information — or else they are either making a mistake or not really trying to solve the task.
In other words, most high-stakes deployment situations will give the AI at least this much entanglement. Therefore, having less than the minimum entanglement becomes a strong signal of something unusual going on — typically an evaluation, a simulation or roleplay scenario, or an interaction with a user who doesn't really care about the answer. Different AIs might react to this signal differently. For example, a scheming AI might reason about it explicitly to gain evaluation awareness. However, many AIs will instead "subconsiously" notice that they seem to have much less context than expected in a typical interaction, and start behaving off-distribution (as reported here). Either way, the test becomes much less informative of the AI's deployment behaviour.
This sets a lower bound on the complexity of any testing environment, which in turn affects the resources (cost, time, etc...) required to create an effective evaluation. (This deserves some caveats and further discussion, some of which is in the previous post, If This Were a Test, How Much Would It Cost?.)
(2) Higher minimum entanglement means more opportunity for spotting inconsistencies
All of our arguments so far would work even if the individual pieces of information that the AI gets were perfectly independent of each other. With higher minimum entanglement, our test environments need to be more complex, which makes them more difficult to create.
However, in practice, the information the AI gets won't be neatly factored into independent buckets. If we make any of the information up14, we risk creating inconsistencies, which the AI might notice.15 At best, this means that the cost of creating tests would grow linearly with the amount of information we need to make up. However, it seems likely that the difficulty grows faster (e.g., with the number of interactions between facts).
As a result, the lower bound from (1) might be higher than it might naively seem.
(3) Actual entanglement is higher than minimum entanglement.
In practice, the difficulty of creating effective tests will depend on the actual entanglement. If we decide that making AIs easier to test is important, we could start deliberately reducing their exposure to unnecessary information during deployment, in order to make them easier to test. However, in practice, we have not yet started with this mission at all, much less pushed it to the theoretical limit of minimum entanglement (which likely wouldn't be cost-effective anyway).
As a result, we should think of the cost of test-creation as being lower-bounded by actual entanglement, which is much higher than the minimum.
(4) Conjecture: Many high-impact tasks have high entanglement.
Finally, there are many reasonably low-entanglement tasks (vacation recommendations?) or even some tasks that are both low-entanglement and important (Riemann hypothesis?). However, we suspect that the most important tasks will have high entanglement. For example, accelerating AI R&D within an AI company, curing cancer, or making geopolitical decisions.
In other words, yes, there will be many tasks where we could afford to create perfectly realistic tests that would fool even a future ASI. But these are probably not the tasks where those tests are needed the most.
Footnotes
-
Or, more generally, any "intelligence" or process doing the solving. ↩
-
I don't think that any of the existing concepts — e.g., in information theory, computational complexity, or some other field — give a perfect operationalization of the concept we are looking for here. However, I might easily be wrong about this; if so, please let me know!
Also, admittedly, the word is not great. Partly, this is because of the connotation with quantum physics. Partly, there are several closely related things where the name would also fit — for example, the fact that facts about the world — including the ones the AI observes — are not independent (and so they are "entangled together"). There is also the issue that "entanglement" suggests the relationship is symmetric, while the connection between an AI and the environment is asymmetrical — the AI receives information and affects the world in response, but the amount (or kind) of information going in each direction won't be the same. ↩
-
I'm not clear on how much this active-sensing part matters or how to formalize it, but it seems like it might be relevant. An AI that can choose what to look at might need to be treated differently from one that passively receives information. ↩
-
Reading this, you might be thinking about Shannon entropy and mutual information, and these may well be relevant concepts. But at this point, I'm not clear on what the best operationalization is — whether it should be a single number, some more multi-dimensional thing, or something else entirely. I want to avoid getting anchored by treating, say, mutual information as if it's definitely the right notion here. ↩
-
This isn't a perfect solution, but it's pointing in a hopefully reasonable direction. The general issue that needs solving is that you can always trade entanglement for computation. ↩
-
In a sense, this is a version of the oft-repeated point that you cannot "just" replace an agent with a planning oracle, because most complicated tasks cannot be "one-shotted" by specifying a "non-agentic program". Rather, those plans will involve the need to reconsider and revise the plan in the course of its execution, as well as reasoned adaptation/interpretation of the plan according to the specific circumstances encountered. The greater the number of such points of intervention, the more unviable it is to execute the plan in a "non-agentic" way. (Mateusz: The best existing reference on this topic that I'm familiar with is this comment by Nate Soares.) ↩
-
This connects to a broader issue in AI safety: People sometimes propose to decompose a task into smaller pieces with the rationale that the individual tasks are easier, and so we can get away with using a weaker AI that is less dangerous. Or we might hope that the individual tasks will be easier to monitor. Or the decomposition might allow us to give each individual AI a smaller amount of context, which would make scheming and evaluation gaming harder.
A crucial worry is that this framing obscures the fact that finding the right decomposition and assembling the solutions of the sub-tasks into a solution of the original task are often the hardest parts of the problem. So the decomposition might not have given us that much after all. In the language of entanglement: If we rely on decomposition, the task of finding the decomposition and assembling the final solution might have the same minimum entanglement as the original task. ↩
-
Technically, the complexity of an infinite class of problems, which forces us to write an actual algorithm, instead of a lookup table. ↩
-
By uncertainty, I don't necessarily mean a probability distribution. It might be Knightian uncertainty, where you just know the task is one of several possibilities, but you don't have a prior over them. ↩
-
This conjecture admits a dual: On some tasks — the ones on which performance degrades sharply — you can notice sharp/non-linear/discontinuous rises in performance (whatever that means) as you cross some level of information provided to the AI. ↩
-
I'm not fully confident in these particular examples — the self-driving car might handle some wrong inputs gracefully, and "approximately correct" taxes might be good enough for some purposes. What I'm pointing at is the distinction between these two types of degradation, which I think is real (even if my specific examples aren't perfect). ↩
-
One caveat: while the actual entanglement has been increasing, the minimum entanglement has been decreasing. Smarter AIs can achieve a certain given level of performance having received less information about the environment, because they have better biases/priors, more capacity to extract useful patterns from limited data, etc. For example, you need to prompt the model less and less for most tasks to get it to do what you want.
If this is a good way of thinking about this, it complicates the type signature, making minimum entanglement depend not just on the task and the level of performance, but also on the type of AI trying to solve the task.
Alternatively, one could think about this as follows. Decreasing apparent "minimum entanglement" is actually a symptom of increasing ["a priori" actual entanglement]. The AI needs less information ("apparent" actual entanglement), because it has already acquired some amount of entanglement with the environment (/ distribution over environments) of this sort of task during training. ↩
-
Query complexity gives tools for proving lower bounds on how much interaction a solver needs. Distortion measures the worst-case welfare loss from using rankings instead of utilities. In other words, it asks "how much performance are we losing by using a less detailed task description". For a reference, check Anshelevich et al., "Distortion in Social Choice Problems: The First 15 Years and Beyond," IJCAI 2021. ↩
-
Crucially, if we want to test hypothetical situations, we do have to make things up; or else the situation would be real. The best case here is what I would call "on-policy testing": Me testing what an AI would do when used for writing LessWrong posts and grant applications (which I already do and use AI for), or an AI company testing what their AI would do when helping with AI development (which they are already doing). As we argued in a previous post, this still requires making up some things. But much less if each of us ran tests on something we have no connection to.
However, note that this "on-policy testing" approach doesn't let us test the situations that matter the most, such as behaviour during genuine takeover opportunities. ↩
-
I sometimes encounter the proposal to introduce deliberate inconsistencies during deployment, in order to prevent the presence of inconsistencies, to serve as a reliable signal of being in evaluation. I mostly just think this is a bit silly and won't work, for various reasons. However, this post offers a nice way to articulate one of the objections: Yes, you can introduce inconsistencies in the information that is mostly irrelevant to the task. However, you can't do this with the critical information, because if you did, you would no longer get an acceptable solution. As a result, the AI can mentally assign much higher importance to inconsistencies in the crucial data — those are the ones that point to an imperfectly created test environment. ↩