The Human Substitution Test as a Sanity Check for AI Evaluations
TL;DR: We suggest a sanity check for proposed evaluation or AI oversight schemes: Imagine the AI was replaced by a competent, strategic human — someone who knows they might get evaluated and has their own agenda. Would the evaluation still work?
When we apply this mental move broadly, to all AIs and evaluations at once, we get a rather discouraging picture: The questions we care about the most — such as "Is it safe to give this AI more power?" — correspond closely to questions where we already know that human evaluations are unreliable, often to the point of being so completely hopeless (or costly) that we don't even attempt them.
This post is part of a collection of ideas about the limitations of AI oversight. It can be read standalone.
The Human Substitution Test
Here is a mental move we find useful for thinking about AI: replace the AI with a human and see how your intuitions about the result change. More precisely, imagine replacing the AI by someone who may have goals of their own and who is at least as smart, strategic, knowledgeable, and aware of the context as a competent human. Then ask whether whatever we're considering — a safety measure, a deployment decision, an evaluation — would still make sense.
This isn't meant to be an anthropomorphisation. In many ways, AIs behave very differently from humans, and this move tells us nothing about how an AI will behave. What it gives us is a lower bound on the difficulty of the problem:1 if something wouldn't work against a strategic human, it currently works for AI only because the AI isn't capable enough to defeat it yet.23
This post is about applying the move to AI evaluations.
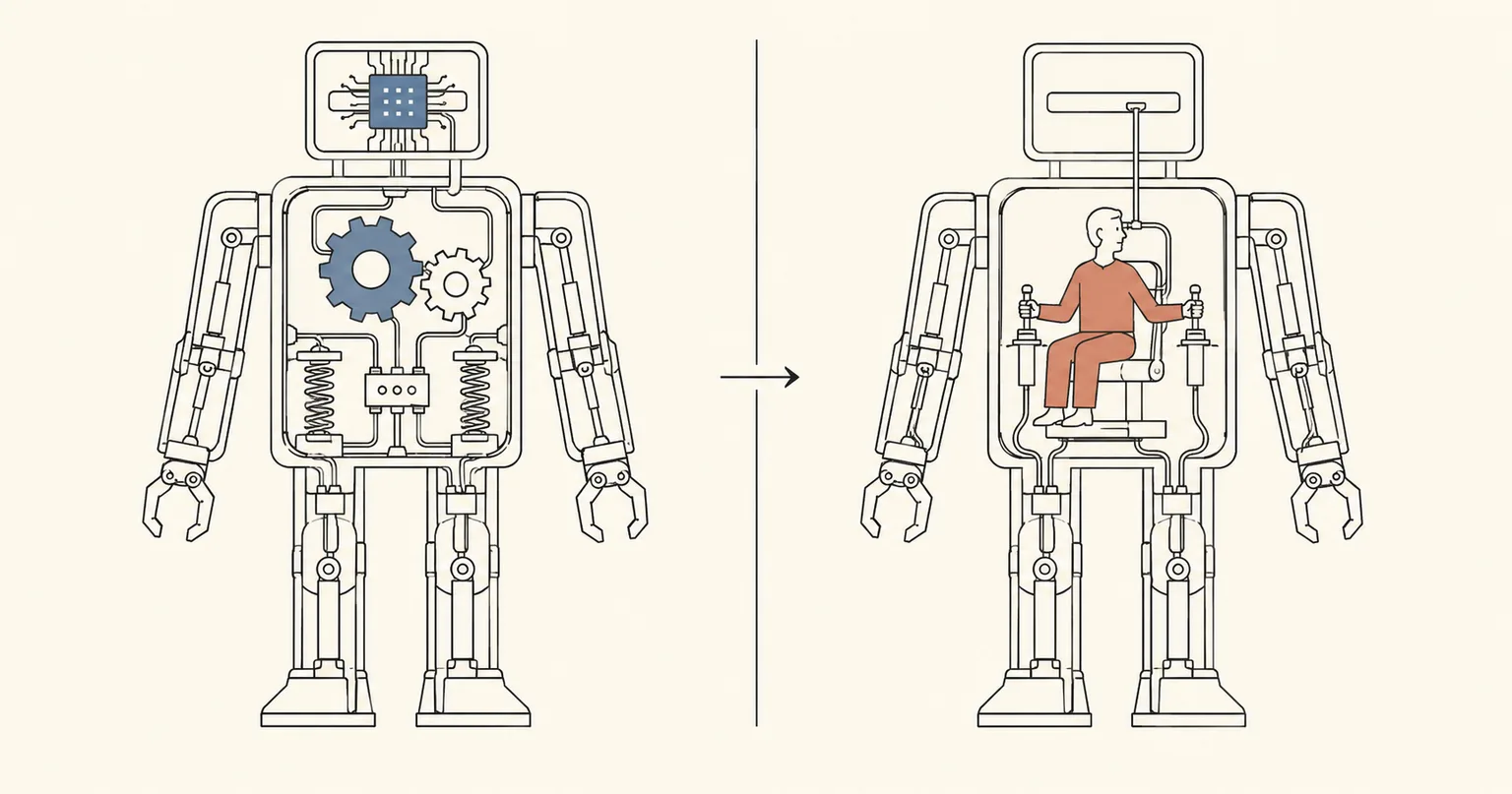
Evaluations at Escalating Difficulty
Let's start with an easy case: Suppose we want to know whether an AI can translate French. We give it test passages and check the results. For humans, the analogy is a translator taking a competency exam. This works — the translator has no reason to hide their abilities.4 And the same applies to most capability evaluations, for both humans and AI.
Now, take a harder case: We want to check whether an AI assistant gives good, balanced advice rather than subtly steering users toward choices that benefit the AI's operator. We review a sample of the AI's outputs and they look fine. For humans, the analogy is an employee whose performance is being reviewed. But humans generally know when their work is likely to get reviewed, and they will be on their best behaviour when it matters. We do get some signal, but it is filtered through the employee's awareness of being watched. And the better they understand the review process, the less informative it becomes.
As an ever harder case, suppose we want to test whether an AI will behave reliably when no one is watching — whether it will leak sensitive data, pursue hidden objectives, or abuse access it has been given. For humans, this is analogous to testing whether an employee will steal or whether a contractor will sabotage a project. Crucially, this is something for which we don't even have a direct test. What we do instead is install cameras, separate duties, require co-signatures, and run audits — structural constraints and traceability, not tests of character. The idea of "testing someone's honesty and relying on the result" is not something any serious security practice depends on.
Finally, suppose we want to determine whether an AI is safe to deploy at scale — whether it can be trusted with significant autonomy and real-world influence. For humans, the analogy is: can this person be trusted with power? Notably, we generally don't evaluate humans for this: We don't test politicians for corruption before giving them office. We don't test executives for recklessness before giving them control of companies. It just wouldn't work; evaluation as a tool for this job is so obviously insufficient that it barely registers as an option.5 Instead, we build constitutions, separation of powers, term limits, independent oversight, etc.
To be clear about the logic behind "the Human Substitution Test": none of this requires the AI to be human-like6. The test's conclusions are worth listening to as soon as we expect to eventually get AI that: (1) can model the fact that it might get evaluated7, (2) might have objectives that don't perfectly align with those of the evaluator, and (3) is capable of adjusting its behaviour in response to the fact that the evaluation might exist8.
Naturally, the test may be even more relevant in the context of AIs that are trained on largely human-generated corpora or trained to imitate human assistants. However, this is by no means required for this test — the properties (1-3) should be expected from any AI that is at least as smart as a human on the relevant dimensions.
Most Safety-Critical Evaluations Already Fail for Humans
Now zoom out and imagine AI has been deployed across the economy and society, across all the domains where it might be valuable. What are all the evaluations we would like to run?
To give a few examples: We would want to know whether AI won't act against the interests of its users when giving medical, legal, or financial advice. Whether it won't leak confidential data. Whether it won't cut corners when managing critical infrastructure. Whether it won't try to bypass guardrails and gradually undermine human oversight. Whether it will try to take control once it is capable of doing so.
But consider some human analogies of these questions.
Do we evaluate job applicants for "misalignment" that will manifest only after they get the job? Do we ask them things like "Will you steal from the cash register when nobody is looking"? (No; we install a security camera instead.) Do we ask whether they will commit fraud or leak confidential data? (No; we use things like background checks, gradual increases in authority, and structural checks.) Do we have routine evaluations for whether people are prone to lying? (Polygraphs are famously unreliable, and most courts won't even admit them as evidence.) Do we evaluate CEOs for "will they abuse power once they get it"? (Not exactly.)9
The evaluations we would most want for AI safety are the kind that already don't work for humans, to the point where, in most cases, we don't even try. Not because we wouldn't value the information, but because the tests obviously wouldn't work against someone who understands what's being tested and has a reason to game it.10
This pattern of evaluation failures isn't a coincidence. Rather, the evaluations that matter most for safety tend to be about dispositions — what one would do when they aren't being observed, when they have a chance to act against the evaluator's interests. But somebody strategic will simply behave well when they are being watched. (The employee who only steals when the cameras are off. The advisor who gives biased recommendations only when confident the client won't notice. The politician who abuses their power only when they have enough of it to escape the consequences.11) The strategy of behaving well when you might be watched produces an excellent track record, right up until the moment it causes harm. And this is precisely why evaluation-based safety assurances are unreliable in the cases where they matter most.12
Where the Human Analogy Breaks
To be clear, the human substitution test is not perfect. There are important disanalogies between AI and human evaluations.
Reasons AI evaluation might be easier than human evaluation:
Interpretability. We can inspect the AI's internal reasoning to an extent that would be impossible with human neuroimaging (for practical or moral13 reasons). This makes AI evaluations vastly more effective than they would be otherwise, and gives those evaluations a chance for success where human evaluations would be doomed to fail.
However, there are reasons to think that interpretability is not a silver bullet solution. The closest human analogues — lie detectors, surveillance, mind-reading in fiction — are imperfect and can be defeated by someone who knows about them. Moreover, AI interpretability does not work well enough yet, and it is unclear whether it will catch up in time. (If it did, it could solve a significant fraction of alignment issues — at least in the near/medium term. But will it?) Ultimately, the thoughts of superintelligent AIs might be so far beyond us, and so alien to us, that any attempt to translate them into human language would be so inaccurate as to be useless (including for the purpose of detecting deception, scheming, etc).14
Reproducibility and non-problematic A/B testing. Unlike with humans, we can re-run the same tests many times or run the AI on multiple inputs, without the AI adapting its behavior to the test based on prior tests.15
Information control. We can restrict what the AI knows about its situation more tightly than for humans — at least for current systems with limited memory and context; see the point about entanglement below.
Fewer constraints from law and ethics. Many of the things we can do in an AI test would be illegal or unethical to do with humans: lying, manipulation, bodily harm (cf. ablation studies), causing emotional distress, etc.16
Reasons AI evaluation might be harder:
A capable AI may be more strategic than humans, be able to deceive better, and pay attention to different things. The human substitution test mostly gives a lower bound on what the AI might do — it cannot rule out the possibility that a sufficiently advanced AIs will use a strategy that would be unavailable to a human. For example, an AI might notice cues about being tested that a human would miss — statistical patterns in inputs, timing anomalies, metadata inconsistencies.
Coordination between instances. While we might try to reset the AI between tests, different instances of the AI might coordinate without any explicit communication channel, for example, through persistent effects on their shared environment. And while humans also share information about tests with each other (e.g., websites gathering information on hiring processes at specific companies), the AI might get better at this.
Note also that a powerful AI might even find ways to reason consistently across different copies acausally, without external help.
Complex tasks might be inherently expensive to test. Valuable tasks require the AI to interact with real-world details (such as conversation history, connected tools, rich databases, and information about the current state of the world). Fabricating a convincing test version of all of this is extremely expensive. (For more context on this, see the post If This Were a Test, How Much Would It Cost? and the related concept of (minimum) "entanglement".) Since we want the AI to solve problems that are currently beyond us, the AI solving those tasks might eventually be paying attention to an unprecedented amount of details, which might be unprecedentedly expensive to test.
Which Types of Evaluation Might Still Work?
If straightforward evaluation breaks against strategic AI, what kinds of evaluation might still work?17
It helps to distinguish two functions that "evaluation" currently serves. One is measurement: how good is this particular AI at translation, coding, or medical diagnosis? Measurement can often work because the system typically has no reason to hide capabilities that we want it to have. The other is oversight: Is it safe to deploy this AI? Can it be trusted with autonomy? Or should we retrain it, recall it, or put more guardrails around it? Oversight is what breaks, because it requires the evaluation to work even when the AI has reasons to game it.18
What has historically worked for the "oversight" problem with humans are structural approaches:
- Monitoring and track records — ongoing observation, rather than one-time tests. The rate of error-catching might be low, but if we do it over a longer period, our chances increase significantly. (Though this doesn't prevent long cons, where the final prize is significantly more valuable than what comes before it.)
- Institutional checks and balances — things like separation of powers, independent oversight, and competing interests that make coordinated deception harder.
Somewhat related: Information within institutions is often fragmented, which creates cracks that can be used by external auditors.19 - Incident reporting and accountability — mechanisms that increase the chance that misbehaviour will have consequences, even when it isn't detected in time to prevent the harm.
- Designing for evaluability — instead of building powerful blackbox AIs to be capable and worrying about evaluation as an afterthought, evaluability could be a crucial consideration that determines which types of AIs we build in the first place. An existing example of this is the plan to keep LLM chain-of-thought legible and monitorable, rather than applying optimisation pressure to it or replacing it with "neuralese". However, we could go much further and actively look for architectures and paradigms that are easier to evaluate than current LLMs.20
None of these approaches is a silver bullet. Rather, unlike straightforward evaluation, these are tools that have proven to be somewhat robust against strategic behaviour.
Vojta: Personally, my preferred approach would be to bide our time with AI progress and solve alignment first. Or focus on automating trusted processes, as opposed to building general black-boxes. (Oh well.)
Tomáš: I think that the four points above (along with others) may be significantly helpful, but they need to be combined into a solid construction rather than a pile of sticks. One point of this post is that many pre-deployment tests don't add much beyond a clutter of scattered sticks, and so we should start considering other options.
Conclusion
AI evaluation currently works tolerably well, creating an expectation that it will continue to be useful as AI becomes more capable. The human substitution test suggests this won't pan out: most of the evaluations that matter most for safety are operating in a regime where the human analogues have already failed, or where we never even attempted them in the first place.
This doesn't mean evaluation is useless: Measurement continues to work. Cooperative evaluation — where the AI benefits from demonstrating trustworthiness — may also survive. And evaluation will remain useful when combined with structural constraints. But we should not use evaluation as the first line of defense — or worse yet, as the only line of defense — because that use case will eventually stop working. Where by "eventually", we mean "much sooner than many people expect".
The following posts develop the structural argument: the concrete cost-of-testing argument (If This Were a Test, How Much Would It Cost?), and the concept of entanglement that underlies it (Entanglement).
Footnotes
-
Yudkowsky's AI in the box experiment is an example of this move. ↩
-
Strictly speaking, the "human substitution test" is a conditional: if at some point AI becomes capable enough, evaluation will stop being informative. But given how hard we are trying to build AIs that are capable and autonomous, it might be fair to view this as when rather than if.
Note also that this move seems to have a decent track record — better, at least, than the heuristic that "the AI is just a non-agentic tool." ↩
-
The move also doesn't imply that the AI in question will behave undesirably. After all, the AI might be aligned, in which case it won't have a reason to game the evaluation despite having the ability to do so. However, this response goes counter to the reason why we are doing evaluations in the first place — not being sure which AI we are dealing with, and generally making sure things go well in all worlds, rather than just in the more convenient ones. ↩
-
Unless they're sandbagging — deliberately underperforming to seem less capable, for example. Humans frequently do this to avoid being given harder work, and we have seen AIs do this in the lab to avoid raising suspicions. This shows that it matters not only what sort of evaluation we are running, but also why we are running it. ↩
-
We do use some evaluation-adjacent processes — background checks, security clearances, vetting. But these primarily check history and associations, not dispositions. And even these are routinely defeated: people with security clearances have sold state secrets throughout history. ↩
-
Or have any philosophically controversial properties like consciousness. ↩
-
It is not necessary that the AI can tell when exactly it is getting evaluated and when not, only that it understands that the evaluation might happen in general. For more discussion, see our earlier post Deployment Awareness Matters More Than Evaluation Awareness and the section on "Evaluation gaming with no evaluation or deployment awareness". ↩
-
This third part is where tools like interpretability and chain-of-thought monitoring become important. When you ask current LLMs about how they would scheme if they were misaligned, they often mention that scheming is hard because these tools make you likely to get caught. In other words, LLMs would, in principle, be able to come up with strategies for defeating evaluations, but these tools make it hard to actually adopt those strategies.
That said, relying on the assumption that AIs will never be able to think unmonitored thoughts seems reckless. (See Circumventing interpretability: How to defeat mind-readers.) ↩
-
Technically, we can sometimes evaluate an applicant based on their track record. Unfortunately, in the case of AI evaluations, we often do not have a representative track record. ↩
-
In an earlier draft, we also listed the example of not evaluating political candidates for honesty. (Though current politics has bigger issues than that.) We removed the example from the main text because it feels like too much of a distraction. However, this example points to an interesting minor flaw in my argument: We suspect that if we evaluated political candidates for a bunch of things, such as dark triad traits and basic numeracy, this would improve matters. Obviously, this would be noisy and problematic (who decides what the content of the test is?). People would game it a lot, and powerful people might try to bypass it. That said, the fact remains that this example disproves my claim that most of the evaluations we could run on humans are not used because they wouldn't work. On the other hand, this example does support a broader point, that when it comes to strategic entities, evaluations are not a very reliable oversight method. ↩
-
The pattern isn't limited to humans. Volkswagen programmed its cars to detect emissions tests and reduce pollution only during testing, allowing them to pass evaluations while exceeding legal limits multiple times in normal driving.
(Incidentally, this gives an example of the evaluator getting deceived without any "deliberate deception" by the evaluated entity. Which illustrates that some of the philosophical discussions around intentionality are orthogonal to questions about evaluation gaming.) ↩
-
The "play nice, then act" pattern is one of several counter-strategies available to a misaligned AI. The human analogy makes it especially vivid: it's not a theoretical concern — it's standard human behaviour in adversarial contexts. ↩
-
There's one genuinely novel advantage: if we're confident an AI doesn't have moral status, we can test it more intrusively than we could a human — isolation, repetition, adversarial probing that would be unacceptable to do to a person. This advantage erodes if the AI does have morally relevant properties. ↩
-
For a more detailed list of concerns about interpretability, see Lee Sharkey's Circumventing interpretability: How to defeat mind-readers. ↩
-
Whenever some type of testing becomes a routine part of AI R&D, the AI soon learns this fact as well, by virtue of having read all of the internet. And this will also become a problem here. However, we can at least run A/B tests on a single AI whose memory we reset, instead of having to do so on large sample sizes as we do with humans. ↩
-
This does not make the human substitution test inapplicable: While some AI tests may be illegal to perform on humans, we can still use the human substitution test within a thought experiment, and if we expect the human to foil the test, we can still conclude a capable AI would as well. ↩
-
An obvious and reasonable reaction is that we should just look for alternative approaches that don't rely on observation-based oversight. For example, find some other paradigm than LLMs, something that would be inherently more amenable to science and less reliant on trial and error. But within the context of this post, we will assume that we want to stick with the current paradigm and rely on evaluation. ↩
-
But what if we use the measurement data for oversight? For example, what if we take a genuine measurement of the AI's hacking abilities, then use it to decide whether the AI still seems safe or not? In case this still seems like a viable idea, recall the Human Substitution Test: "Would this strategy seem reliable against a strategic human?" (The answer: No.) ↩
-
An individual human has unified awareness and can coordinate their deception seamlessly. An institution has departments with different information and conflicting interests. AI systems could go either way — but optimisation pressure toward unified awareness would erode these advantages, much as companies under regulatory scrutiny learn to route communications through legal and PR departments, and train employees on what to say to auditors. ↩
-
For example, cognitive emulations, or training narrower models and having a cleaner separation of powers. We are more confident about the claim that "evaluability as a consideration on par with capability" is a good idea and solutions to it will exist, than about any specific existing approaches being the ultimate solution. ↩